The Best Open-Source and Open-Weight AI Models for OCR
Table of Contents
- Introduction
- Understanding Open-Source vs. Open-Weight
- Quick Comparison: Leading OCR Models
- How to Choose the Right OCR Model
- Leading Open-Source and Open-Weight OCR Models
- Benchmark Data and Performance
- Running Models at Home: Power Requirements
- Where to Get the Models
- Cost Considerations and Setup Examples
- Conclusion
Introduction
Optical Character Recognition (OCR) technology has revolutionized how we interact with text in images and documents. From digitizing old books to automating data entry, OCR models are at the forefront of transforming unstructured visual data into actionable insights. In recent years, the landscape of OCR has been significantly shaped by the emergence of powerful open-source and open-weight AI models. These models offer unparalleled flexibility, transparency, and cost-effectiveness, making advanced OCR capabilities accessible to a wider audience, from individual developers to large enterprises. This comprehensive guide delves into the leading open-source and open-weight OCR models, providing insights into their performance, hardware requirements, and the organizations behind their development. We aim to equip you with the knowledge to choose the best OCR solution for your needs, whether you’re running it on a personal computer or deploying it in a large-scale system.
Understanding Open-Source vs. Open-Weight
Before diving into the models, it’s crucial to understand the distinction between “open-source” and “open-weight” in the context of AI models:
Open-Source Models: These models come with their complete source code, allowing users to inspect, modify, and distribute the software freely. This transparency fosters community collaboration, enables custom modifications, and ensures long-term viability and security.
Open-Weight Models: For these models, only the trained model weights are publicly available, while the training code or the full development pipeline might remain proprietary. This allows users to run and fine-tune the models, but restricts deeper modifications or understanding of their underlying architecture and training processes. Open-weight models are often released by companies to encourage adoption and innovation on top of their pre-trained models.
Both categories offer significant advantages over closed-source, proprietary solutions, primarily in terms of accessibility, customization, and cost. For individuals and organizations looking to implement OCR solutions without hefty licensing fees or vendor lock-in, open-source and open-weight models present compelling alternatives.
Quick Comparison: Leading OCR Models
Before diving into detailed descriptions, here’s a comprehensive comparison to help you choose the right model:
| Model | Type | Languages | GPU Required | Min VRAM | Best For | License |
|---|---|---|---|---|---|---|
| Tesseract | Traditional ML | 100+ | No | 0GB | General documents, printed text | Apache 2.0 |
| EasyOCR | Deep Learning | 80+ | Recommended | 2GB | Quick Python integration | Apache 2.0 |
| PaddleOCR | Deep Learning | 80+ | Recommended | 4GB | Chinese text, complex documents | Apache 2.0 |
| DocTR | Deep Learning | Multiple | Optional | 2GB | Flexible OCR pipeline | Apache 2.0 |
| TrOCR | Transformer | Multiple | Yes | 6GB | Handwritten text | MIT |
| Donut | Transformer | Multiple | Yes | 16GB | Document understanding | MIT |
| Qwen2.5-VL | LLM | Multiple | Yes | 6-80GB | Complex visual understanding | Apache 2.0 |
| Llama 3.2 Vision | LLM | Multiple | Yes | 2-30GB | General vision-language tasks | Llama 2 Community |
| Moondream2 | Small LLM | Multiple | Optional | 1GB | Edge devices, low resource | Apache 2.0 |
How to Choose the Right OCR Model
🖥️ If you have no GPU or limited hardware:
- Tesseract: Best for basic printed text extraction
- Moondream2: For simple visual understanding tasks
💻 If you have a consumer GPU (4-8GB VRAM):
- EasyOCR: Quick setup, good general performance
- PaddleOCR: Better for Asian languages and complex layouts
- TrOCR: When you need handwriting recognition
🚀 If you have high-end hardware (16GB+ VRAM):
- Qwen2.5-VL: State-of-the-art performance, complex documents
- Donut: OCR-free document understanding
- Llama 3.2 Vision: General vision-language capabilities
📊 By Use Case:
- Simple text extraction: Tesseract, EasyOCR
- Handwritten notes: TrOCR, Qwen2.5-VL
- Complex documents/forms: PaddleOCR, Donut, Qwen2.5-VL
- Real-time applications: EasyOCR, Moondream2
- Multilingual content: PaddleOCR, Qwen2.5-VL
Leading Open-Source and Open-Weight OCR Models
The OCR landscape is diverse, with models catering to various use cases, from simple text extraction to complex document understanding. We’ll explore some of the most prominent models, categorizing them by their underlying technology and highlighting their strengths.
Traditional Machine Learning-Based OCR Models
These models typically rely on classical computer vision techniques combined with machine learning algorithms for text detection and recognition. They are often more lightweight and can run on less powerful hardware, making them suitable for local deployment.
Tesseract OCR
Tesseract is arguably the most widely recognized and used open-source OCR engine. Originally developed by Hewlett-Packard and later sponsored by Google, it has a long history of development and a robust community. Tesseract is known for its accuracy in recognizing printed text and its support for over 100 languages.
Want to try Tesseract without installation? Visit ocrmd.com/about to try Tesseract.js completely client-side in your browser. For more advanced OCR capabilities, you can also try OCRMD’s premium models with 30 free image/PDF extractions when you sign up! (Disclosure: OCRMD is developed by the author of this blog post)
- Key Features: Supports 100+ languages, LSTM-based, extensive documentation, Apache 2.0 license.
- Best For: General document processing, especially printed text.
- Hardware Requirements: Relatively low. A dual-core processor with 2 GHz and 2 GB of RAM is a minimum, with a quad-core processor and at least 4 GB of RAM recommended for larger text files. Tesseract is primarily CPU-based, with limited GPU support via OpenCL drivers.
- Source: GitHub
- Developed by: Originally Hewlett-Packard Laboratories, later sponsored by Google.
EasyOCR
EasyOCR is a popular Python library designed for ease of use and quick integration. It supports over 80 languages and various writing scripts, making it versatile for many applications. EasyOCR leverages PyTorch for its deep learning models.
- Key Features: Python API, 80+ languages, PyTorch-based, Apache 2.0 license, no handwritten text support yet.
- Best For: Quick integration in Python projects.
- Hardware Requirements: Benefits significantly from GPU acceleration. A modern NVIDIA GPU with CUDA support is recommended for optimal performance. It also requires a CPU that supports the AVX2 instruction set. Minimum 2 GB RAM to run an Open eVision application, 8 GB RAM to compile.
- Source: GitHub
- Developed by: Jaided AI.
PaddleOCR
PaddleOCR, developed by Baidu, is an impressive OCR toolkit known for its high accuracy, especially for Chinese and English text. It offers a comprehensive suite of tools for text detection, recognition, and structured document analysis, including layout analysis and table/formula recognition.
- Key Features: PP-OCRv4 (high accuracy for Chinese/English), 80+ languages, layout analysis, table/formula recognition, Apache 2.0 license.
- Best For: Complex document processing, especially Chinese text and structured documents.
- Hardware Requirements: Running PaddleOCR on GPU significantly accelerates processing speed. Requires CUDA for GPU installation. While specific minimums are not strictly defined, user examples suggest configurations like Windows 10 Pro 64-bit, Intel Core i5-9500 CPU, 64 GB RAM, and NVIDIA GeForce RTX 2060 6GB GPU for efficient use.
- Source: GitHub
- Developed by: PaddlePaddle (Baidu).
DocTR
DocTR (Document Text Recognition) is an open-source library from Mindee that provides a seamless and high-performing solution for OCR-related tasks. It offers multiple text detection and recognition architectures and supports both PyTorch and TensorFlow.
- Key Features: Multiple text detection/recognition architectures, PyTorch/TensorFlow support, Apache 2.0 license.
- Best For: Flexible OCR pipeline.
- Hardware Requirements: GPU support is available, often facilitated through Docker images for easier setup.
- Source: GitHub
- Developed by: Mindee.
Large Language Model (LLM)-Based OCR Models
The advent of large language models has brought a new paradigm to OCR, enabling more sophisticated understanding of document content beyond mere text extraction. These models often excel in handling complex layouts, contextual understanding, and even handwritten text.
Microsoft TrOCR
TrOCR (Transformer-based Optical Character Recognition) is an end-to-end text recognition approach developed by Microsoft Research. It utilizes a Transformer-based architecture, making it particularly strong in recognizing handwritten text.
- Key Features: Transformer-based, strong handwriting recognition, MIT license.
- Best For: Handwritten text recognition.
- Hardware Requirements: Requires GPU for efficient inference. Users have reported memory issues with 10GB GPU memory for fine-tuning, suggesting higher VRAM for training. As a Transformer-based model, it benefits significantly from GPU acceleration.
- Source: Hugging Face
- Developed by: Microsoft Research.
Donut
Donut (Document Understanding Transformer) is an OCR-free document understanding model developed by Clova AI. It’s designed to perform document understanding tasks without relying on a traditional OCR pipeline, making it highly effective for structured documents.
- Key Features: OCR-free document understanding, strong performance on structured documents, MIT license.
- Best For: Document understanding without traditional OCR pipeline.
- Hardware Requirements: A GPU with at least 16GB of memory (e.g., NVIDIA RTX 3090) is recommended for fine-tuning. For inference, it can run on CPU with 32GB RAM and a 12th Gen Intel Core i9, but it will be slower (3-4 seconds per image).
- Source: GitHub
- Developed by: Clova AI (LINE Corporation).
Qwen2.5-VL
Qwen2.5-VL is a multimodal large language model series developed by Alibaba Cloud’s Qwen team. It demonstrates advanced visual language understanding capabilities, high accuracy on complex layouts, and support for multiple languages.
- Key Features: Multimodal, advanced visual language understanding, high accuracy on complex layouts, multiple languages, Apache 2.0 license.
- Best For: Complex visual language understanding tasks.
- Hardware Requirements: Requires significant VRAM. For example, Qwen2.5-VL-3B needs 11.5 GB (FP32) or 5.75 GB (BF16), while the 7B model requires 26.34 GB (FP32) or 13.17 GB (BF16). NVIDIA A6000 (48GB), A100 (80GB), H100 (80GB) are recommended for larger models, though an RTX 4090 (24GB) can run the 7B model. Minimum 32GB RAM (64GB or more for vision-intensive tasks), and a powerful CPU (e.g., AMD EPYC 64-core / Intel Xeon 32-core for larger models) are also recommended. At least 50GB free SSD space is needed.
- Source: GitHub, Hugging Face
- Developed by: Qwen team, Alibaba Cloud.
Llama 3.2 Vision
Llama 3.2 Vision, developed by Meta AI, is a collection of instruction-tuned image reasoning generative models. It excels in general visual understanding, contextual text extraction, and supports multiple languages, making it suitable for combined visual-language tasks.
- Key Features: General visual understanding, contextual text extraction, multiple languages, Llama 2 Community License (open-weight).
- Best For: Combined visual-language tasks.
- Hardware Requirements: Requires GPU for inference. VRAM requirements vary by model size: Llama 3.2 1B needs 2.3GB (NVIDIA GTX 1650), 3B needs 6.9GB (NVIDIA RTX 2060), and 11B Vision needs ~10 GB (4-bit mode) or >30 GB (without quantization). At least 16GB RAM is recommended.
- Source: Hugging Face, Meta AI Blog
- Developed by: Meta AI.
Mistral OCR
Mistral OCR, from Mistral AI, is an advanced OCR solution that comprehends each element of documents—media, text, tables, and equations—with high accuracy. While primarily offered as an API, self-hosting is possible for enterprises, leveraging Mistral’s powerful open-source models.
- Key Features: High accuracy in document understanding, handles various document elements, API-first with self-hosting options.
- Best For: Enterprise-grade document analysis and complex data extraction.
- Hardware Requirements: Recommended 16GB VRAM for full precision (for Mistral 7B, which Mistral OCR is based on). Can run on CPU only, but slower.
- Source: Mistral AI
- Developed by: Mistral AI.
Moondream2
Moondream2 is a tiny yet powerful open-source vision language model designed to run efficiently on edge devices with very little memory. It combines strong image understanding capabilities with a remarkably small footprint.
- Key Features: Small size, efficient, strong image understanding, open-source.
- Best For: Edge device deployment, resource-constrained environments.
- Hardware Requirements: Designed for efficiency, can run on devices with limited memory. Specific detailed requirements are less stringent than larger LLMs.
- Source: GitHub, Hugging Face
- Developed by: Vikhyat Korrapati (Moondream).
Idefics2
Idefics2 is another notable open-source multimodal model from Hugging Face, designed for general visual understanding and reasoning tasks, including those involving text in images.
- Key Features: Multimodal, general visual understanding, open-source.
- Best For: Research and applications requiring broad visual reasoning capabilities.
- Hardware Requirements: Similar to other LLM-based models, benefits from GPU acceleration, with VRAM requirements depending on the model size and precision.
- Source: Hugging Face
- Developed by: Hugging Face.
Benchmark Data and Performance
Evaluating OCR models involves looking at various metrics, including accuracy, speed, and their ability to handle different types of text and document layouts. Here, we present benchmark data from recent studies, focusing on both general OCR accuracy and specialized tasks like JSON extraction.
Roboflow: Average Accuracy Across Domains
The following chart illustrates the average accuracy of various OCR models across different domains, as benchmarked by Roboflow. This benchmark focuses on non-document OCR applications, such as localized text examples.
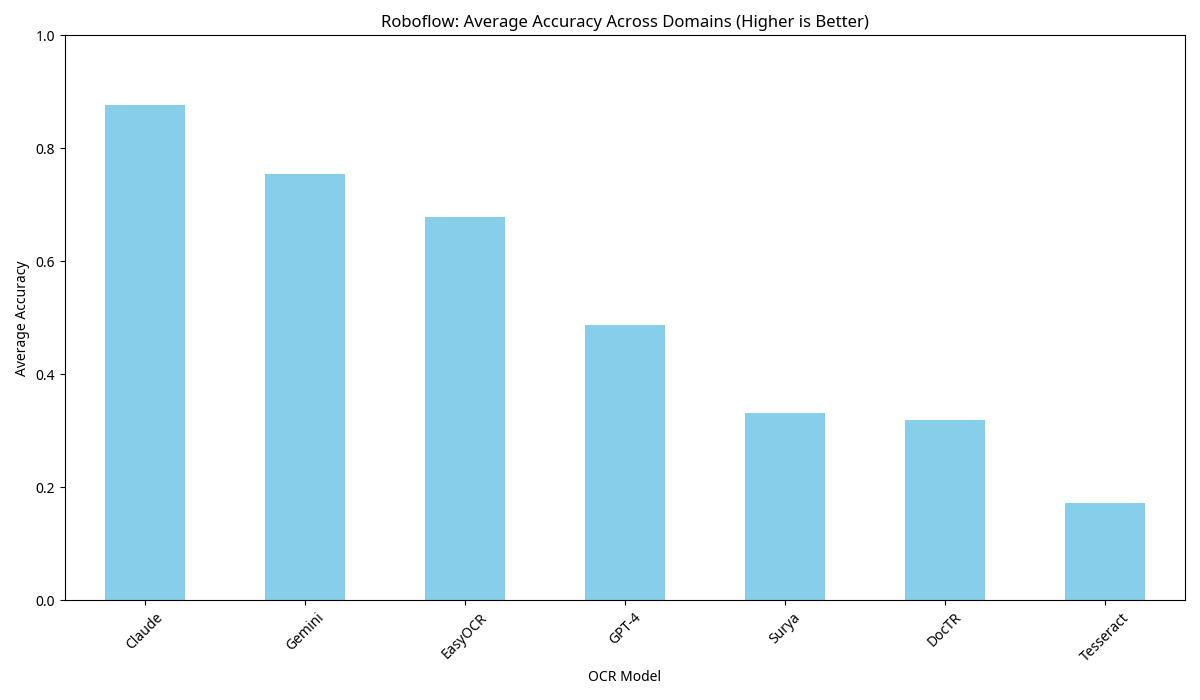
- Key Takeaways: While proprietary models like Claude and GPT-4 often lead in overall accuracy, open-source options like EasyOCR and some LLM-based models demonstrate strong performance, especially in specific domains. This highlights the importance of choosing a model tailored to your specific use case.
OmniAI: JSON Extraction Accuracy
This benchmark from OmniAI focuses on the JSON extraction accuracy of open-source Vision Language Models (VLMs) for OCR. This is particularly relevant for tasks involving structured data extraction from documents.
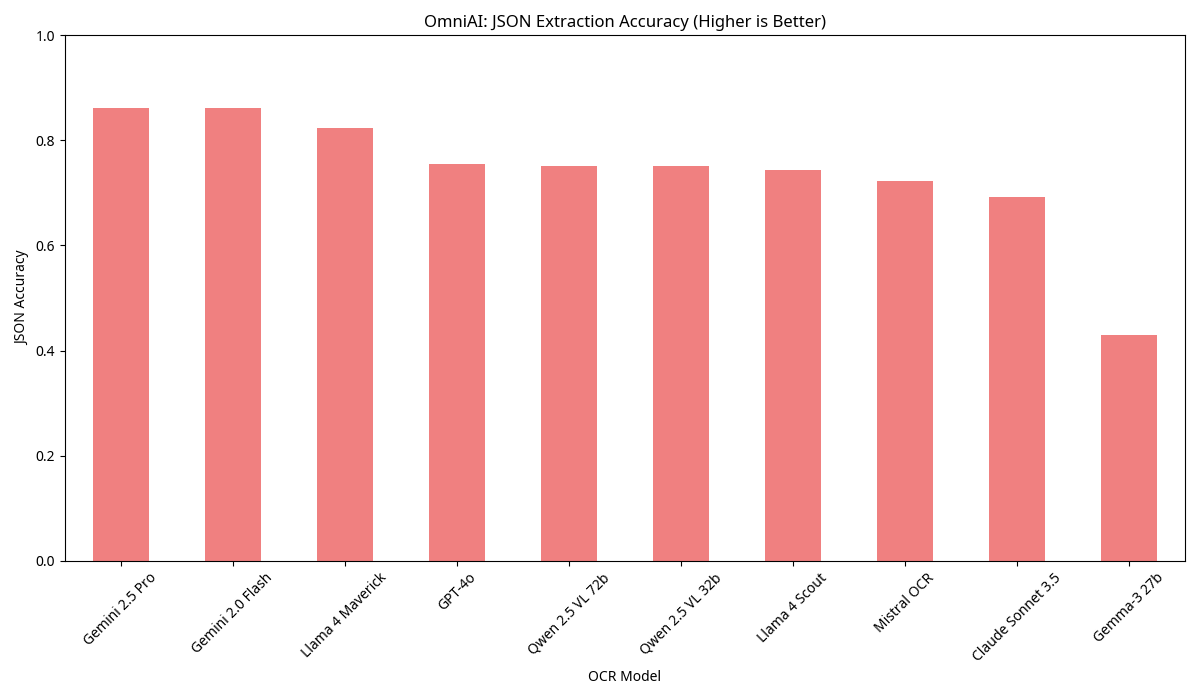
- Key Takeaways: Qwen 2.5 VL models (72B and 32B) show impressive JSON extraction accuracy, comparable to state-of-the-art proprietary models like GPT-4o. Mistral-ocr also performs very well in this specialized task, indicating the growing maturity of open-source VLMs for complex document understanding.
Running Models at Home: Power Requirements and Accessibility
One of the most appealing aspects of open-source and open-weight models is the possibility of running them on local hardware. The feasibility of this depends heavily on the model’s architecture and size.
CPU-Only Options: Traditional OCR engines like Tesseract can run effectively on standard CPUs, making them accessible to almost any home computer. This is ideal for basic text extraction from documents without specialized hardware.
GPU Acceleration: For more advanced models, especially those based on deep learning (like EasyOCR, PaddleOCR, and Transformer-based models), a dedicated GPU is highly recommended. NVIDIA GPUs with CUDA support are the most common choice, and the amount of VRAM (Video RAM) is a critical factor. Models like TrOCR, Donut, and the smaller versions of Qwen2.5-VL and Llama 3.2 Vision can often run on consumer-grade GPUs (e.g., NVIDIA RTX 3060, RTX 4060, or higher with 8GB-12GB VRAM).
High-End GPUs for LLMs: The larger LLM-based OCR models (e.g., Qwen2.5-VL 7B/72B, Llama 3.2 Vision 90B) demand substantial VRAM, often requiring professional-grade GPUs like NVIDIA A6000, A100, or H100. While these are typically found in data centers, the continuous development of quantization techniques is making it possible to run larger models on more modest hardware, albeit with some performance trade-offs.
RAM and CPU: While GPU is often the bottleneck for deep learning models, sufficient system RAM and a capable CPU are still important for overall system performance, especially when handling large datasets or complex pre-processing tasks.
Where to Get the Models
The beauty of open-source and open-weight models lies in their accessibility. The primary platforms for obtaining these models are:
GitHub: Many open-source projects host their code and pre-trained models directly on GitHub. You can clone repositories, follow installation instructions, and often find community support.
Hugging Face Hub: The Hugging Face Hub has become a central repository for pre-trained models, datasets, and demos across various AI domains, including OCR and VLMs. It provides easy access to model weights, documentation, and often includes runnable examples.
Official Project Websites/Organizations: Some models are directly distributed through the websites of their developing organizations (e.g., Meta AI for Llama models, Mistral AI for Mistral OCR).
Always refer to the official documentation and licensing information for each model to ensure proper usage and compliance.
Cost Considerations and Setup Examples
Hardware Costs for Different Setups
Budget Setup (CPU-only): $500-1000
# Install Tesseract (Ubuntu/Debian)
sudo apt update
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
# Python wrapper
pip install pytesseract pillowMid-range Setup (Consumer GPU): $1500-3000
# Setup EasyOCR with CUDA
pip install easyocr
# Requires NVIDIA GPU with CUDA supportHigh-end Setup (Professional GPU): $5000-15000
# Setup Qwen2.5-VL
pip install transformers torch qwen-vl-utils
# Download model (requires 20GB+ storage)Cloud vs Local Deployment Costs
| Deployment Type | Initial Cost | Monthly Cost | Pros | Cons |
|---|---|---|---|---|
| Local CPU | $500-1000 | $0 | No data transfer, full control | Limited performance |
| Local GPU | $1500-5000 | $30-50 (power) | High performance, privacy | High upfront cost |
| Cloud GPU | $0 | $100-500 | Scalable, latest hardware | Ongoing costs, data privacy |
Quick Start Code Examples
Simple OCR with Tesseract:
import pytesseract
from PIL import Image
# Basic text extraction
image = Image.open('document.png')
text = pytesseract.image_to_string(image)
print(text)Advanced OCR with EasyOCR:
import easyocr
# Initialize reader with English and German
reader = easyocr.Reader(['en', 'de'])
result = reader.readtext('document.png')
for (bbox, text, confidence) in result:
print(f"Text: {text}, Confidence: {confidence:.2f}")Document Understanding with Qwen2.5-VL:
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
# Load model and processor
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-2B-Instruct",
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
# Prepare messages
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "document.png"},
{"type": "text", "text": "Extract all the key information from this form"}
]
}
]
# Process for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
# Generate response
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)Conclusion
The open-source and open-weight OCR ecosystem offers unprecedented opportunities for developers and organizations of all sizes. Whether you’re a student working on a homework project with Tesseract, a startup building document processing pipelines with EasyOCR, or an enterprise deploying sophisticated document understanding with Qwen2.5-VL, there’s a solution that fits your needs and budget.
Key Takeaways:
- Start Simple: Begin with Tesseract or EasyOCR for basic needs, then scale up as requirements grow
- Consider Total Cost: Factor in hardware, power consumption, and development time—not just model performance
- Match Hardware to Needs: Don’t over-engineer your solution; a CPU-only setup might be sufficient for many use cases
- Test Before Committing: Most models offer free trials or demos—always test with your specific data before making decisions
- Stay Updated: The field evolves rapidly; what’s cutting-edge today may be standard tomorrow
The democratization of AI through open-source models means that advanced OCR capabilities are no longer exclusive to tech giants. With the right model choice and setup, anyone can build powerful document processing applications that rival enterprise solutions. The future of OCR is open, accessible, and more exciting than ever.
Sources
[1] Roboflow. “Best OCR Models for Text Recognition in Images.” Roboflow Blog. https://blog.roboflow.com/best-ocr-models-text-recognition/
[2] Modal. “8 Top Open-Source OCR Models Compared: A Complete Guide.” Modal Blog. https://modal.com/blog/8-top-open-source-ocr-models-compared
[3] OmniAI. “The best open source OCR models.” OmniAI Blog. https://getomni.ai/blog/benchmarking-open-source-models-for-ocr
[4] Tesseract OCR. https://github.com/tesseract-ocr/tesseract
[5] Jaided AI. “EasyOCR.” https://github.com/JaidedAI/EasyOCR
[6] PaddlePaddle. “PaddleOCR.” https://github.com/PaddlePaddle/PaddleOCR
[7] Mindee. “docTR.” https://github.com/mindee/doctr
[8] Microsoft. “TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models.” https://www.microsoft.com/en-us/research/publication/trocr-transformer-based-optical-character-recognition-with-pre-trained-models/
[9] Clova AI. “Donut.” https://github.com/clovaai/donut
[10] QwenLM. “Qwen2.5-VL.” https://github.com/QwenLM/Qwen2.5-VL
[11] Meta AI. “Llama 3.2: Revolutionizing edge AI and vision with open models.” https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
[12] Mistral AI. “Mistral OCR.” https://mistral.ai/news/mistral-ocr
[13] Moondream. “Moondream.” https://moondream.ai/
[14] Hugging Face. “Idefics2.” https://huggingface.co/HuggingFaceM4/idefics2-8b