The AI Landscape in Flux: A Look at Recent Groundbreaking Developments
The world of artificial intelligence is accelerating at a breathtaking pace. Recent weeks have unleashed a torrent of announcements, from game-changing open-weight models that challenge the dominance of proprietary giants to strategic military partnerships and highly contentious benchmark wars. For developers, researchers, and AI enthusiasts, it’s a thrilling, albeit complex, landscape to navigate. Let’s break down the most significant events.
Kimi K2: A New Titan of Open-Weight Models?

Arguably the biggest news is the release of Kimi K2 by Moonshot AI. This model has taken the community by storm, immediately establishing itself as a formidable competitor to established closed-source models from Anthropic and OpenAI.
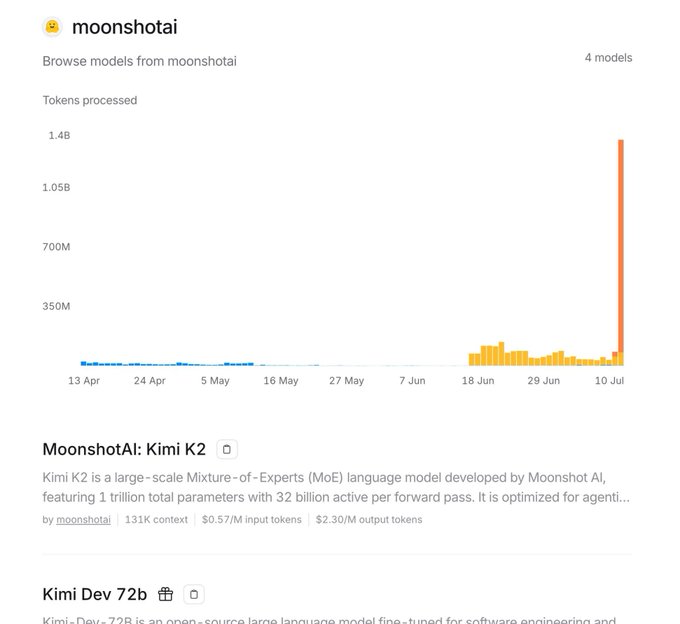
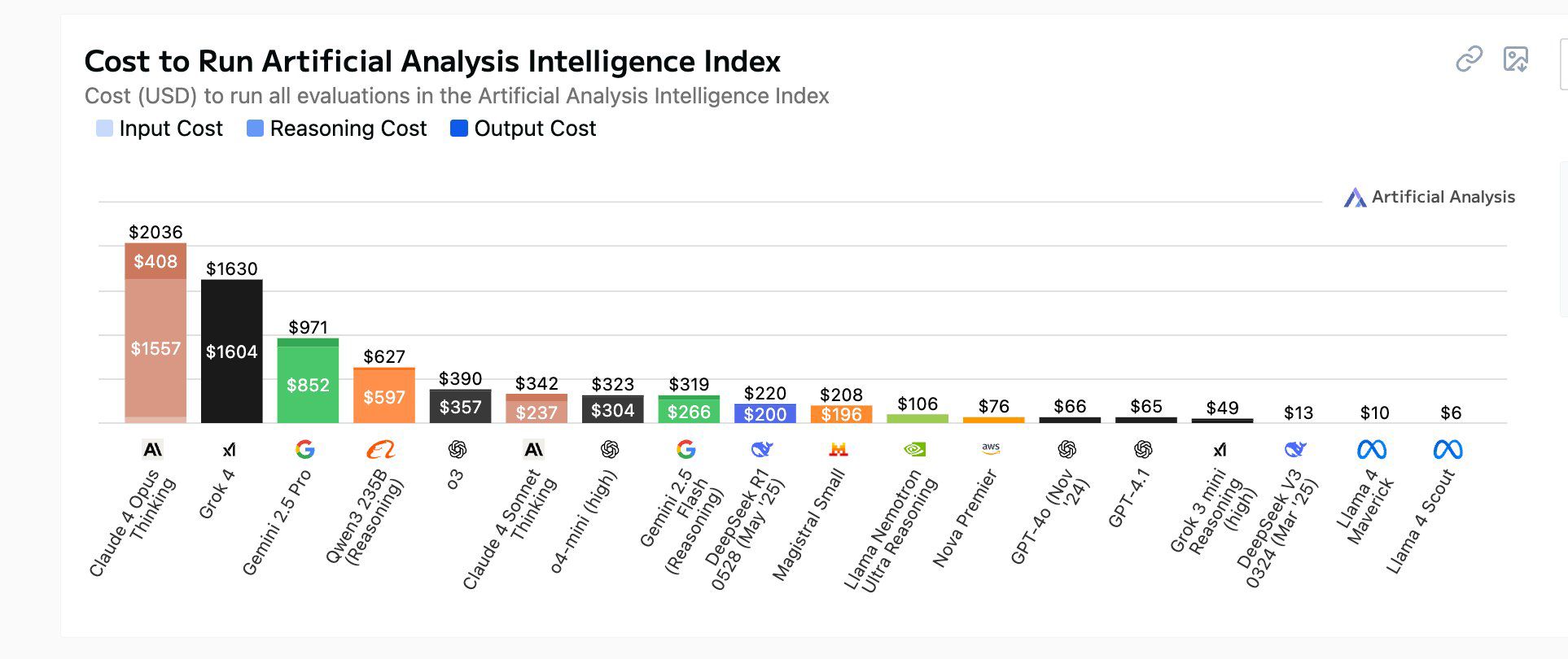
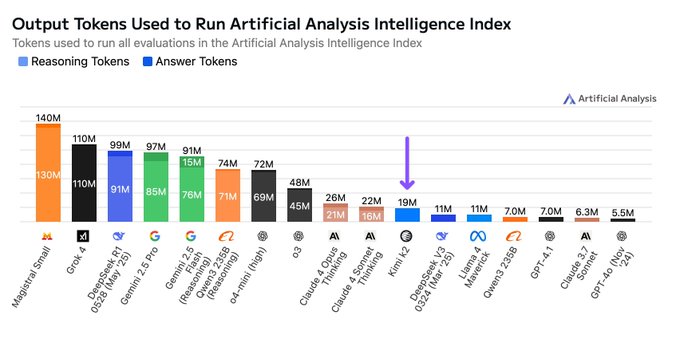
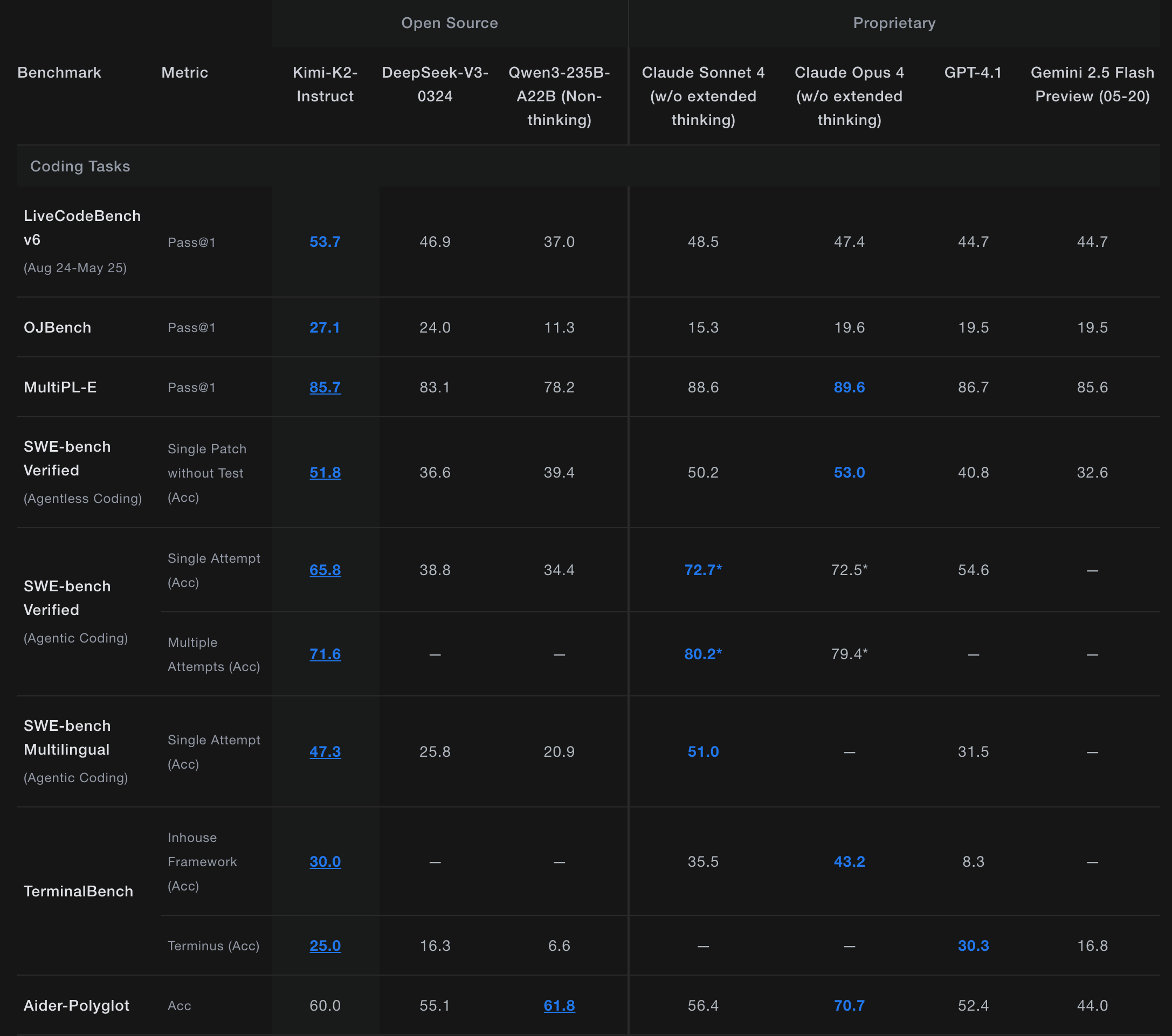
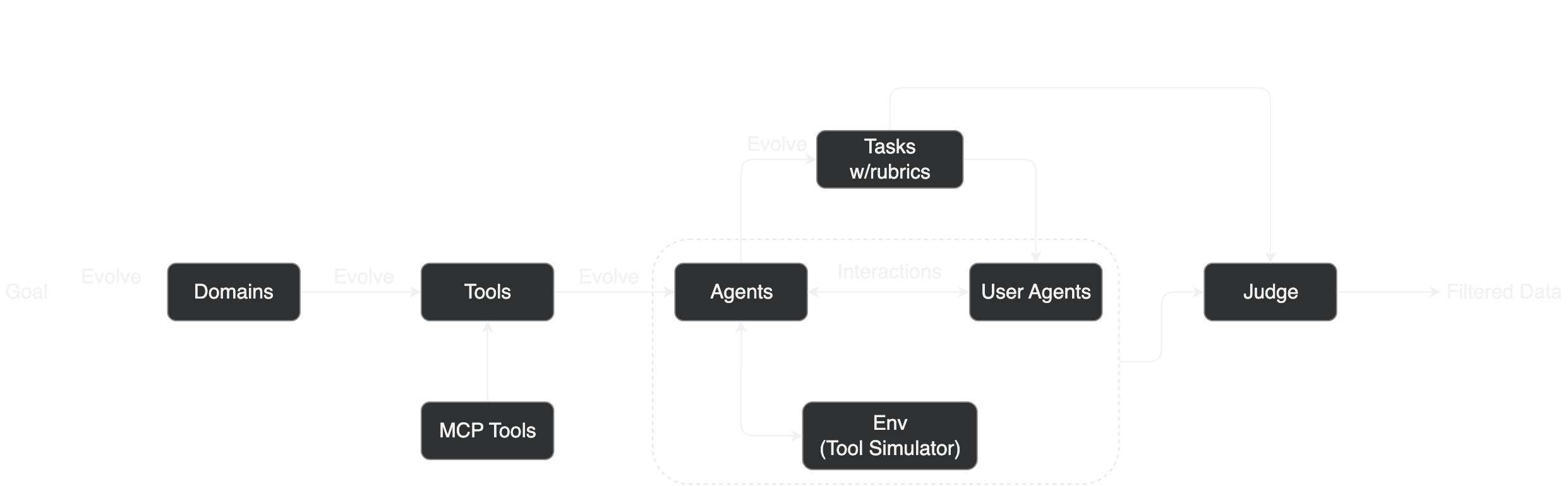
What is Kimi K2? Kimi K2 is a massive Mixture-of-Experts (MoE) model with 1 trillion total parameters, of which 32 billion are active during any given inference task. It’s purpose-built for agentic workflows—tasks requiring autonomous planning, reasoning, and tool use. Most importantly, its weights are openly available, a move that has sent ripples through the industry.
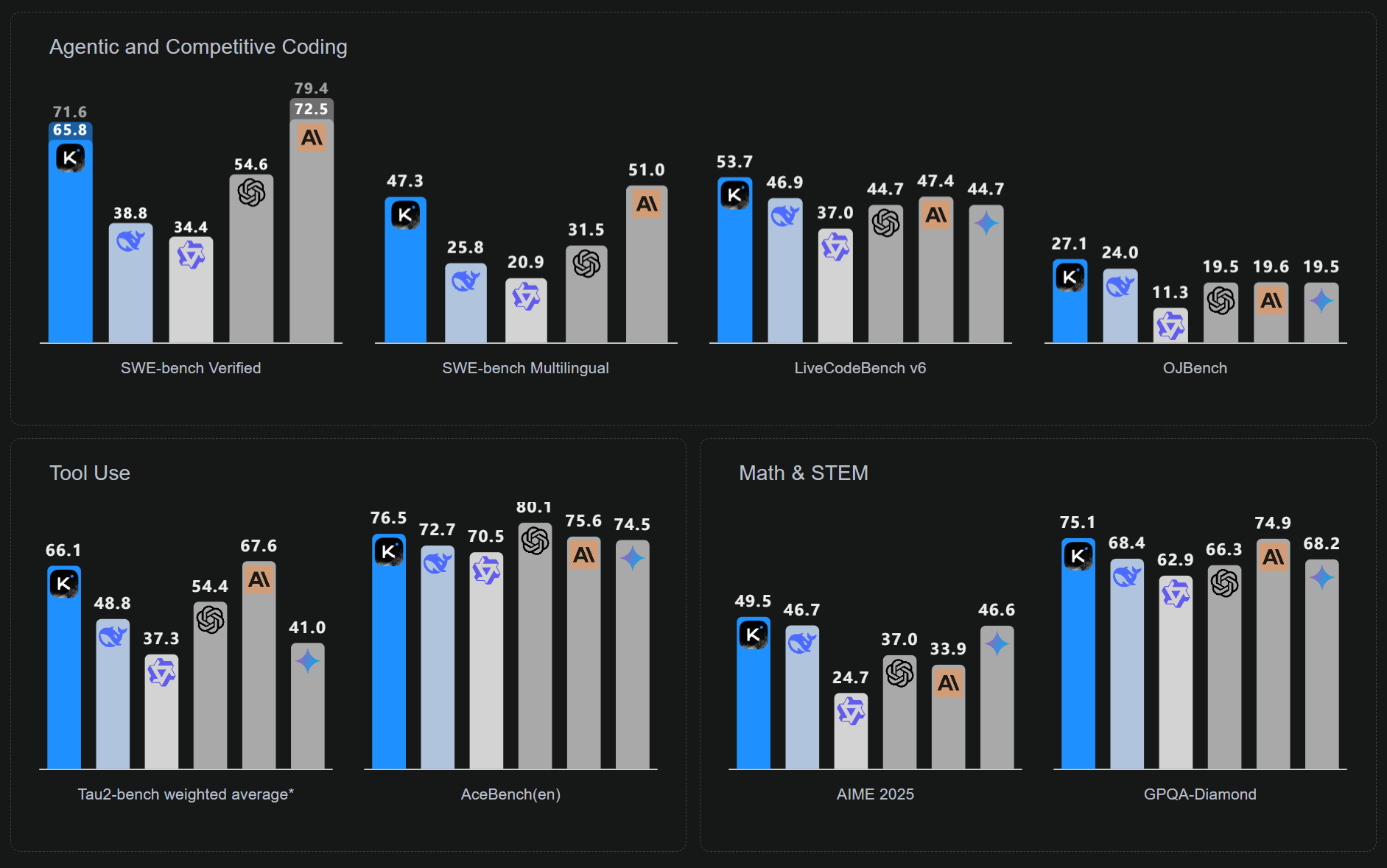
Performance and Capabilities: The benchmarks and initial community tests are nothing short of spectacular. Kimi K2 achieves state-of-the-art results on benchmarks like SWE-Bench Verified, Tau2, and ACEBench, outperforming other leading open-source models. Its core strengths lie in coding and tool use.
Key Highlights:
- Exceptional Coding: Early tests show coding capabilities on par with or even exceeding top-tier models like Claude 4 Sonnet.
- Superior Tool Use: It is one of the first open-weight models to demonstrate robust and effective function-calling capabilities, a critical component for building agents.
- Cost-Effectiveness: The API is significantly cheaper than its proprietary rivals. Some users report that by using an adapter to call Kimi K2 through the Anthropic SDK, the cost can be as low as one-third of Claude Sonnet’s price.
- Recent Knowledge: The model has a very recent knowledge cutoff of April 2025.
- Community Excitement: Kimi K2 shot to the #1 trending spot on Hugging Face upon release, with community sentiment suggesting it’s a “DeepSeek-V4” level of advancement.
The Reasoning vs. Execution Debate: An important technical distinction is that Kimi K2 is positioned as a “non-reasoning” model. Its architecture is optimized for task execution and tool use rather than complex, abstract reasoning. However, it blurs this line by using more tokens for benchmarks than other non-reasoning models, allowing it to process more complex instructions and achieve impressive results that challenge dedicated reasoning models.
The Developer-Friendly License: The modified MIT-based license is extremely permissive. Commercial use is allowed, and only businesses reaching $20 million/month in revenue or 100 million users are required to inform their users that Kimi K2 is being used. This low barrier to entry is a massive boon for startups and indie developers.
You can get started with Kimi K2 here:
- Weights & Code on Hugging Face: huggingface.co/moonshotai
- API & Pricing: platform.moonshot.ai
- GitHub Repository: github.com/MoonshotAI/Kimi-K2
- Free Playground on OpenRouter: openrouter.ai/moonshotai/kimi-k2:free
Grok-4: Benchmark King or Overfitted Contender?
Almost in direct competition with the Kimi K2 buzz, xAI dropped Grok-4. The announcement came with jaw-dropping benchmark scores, but the community has met them with a healthy dose of skepticism.
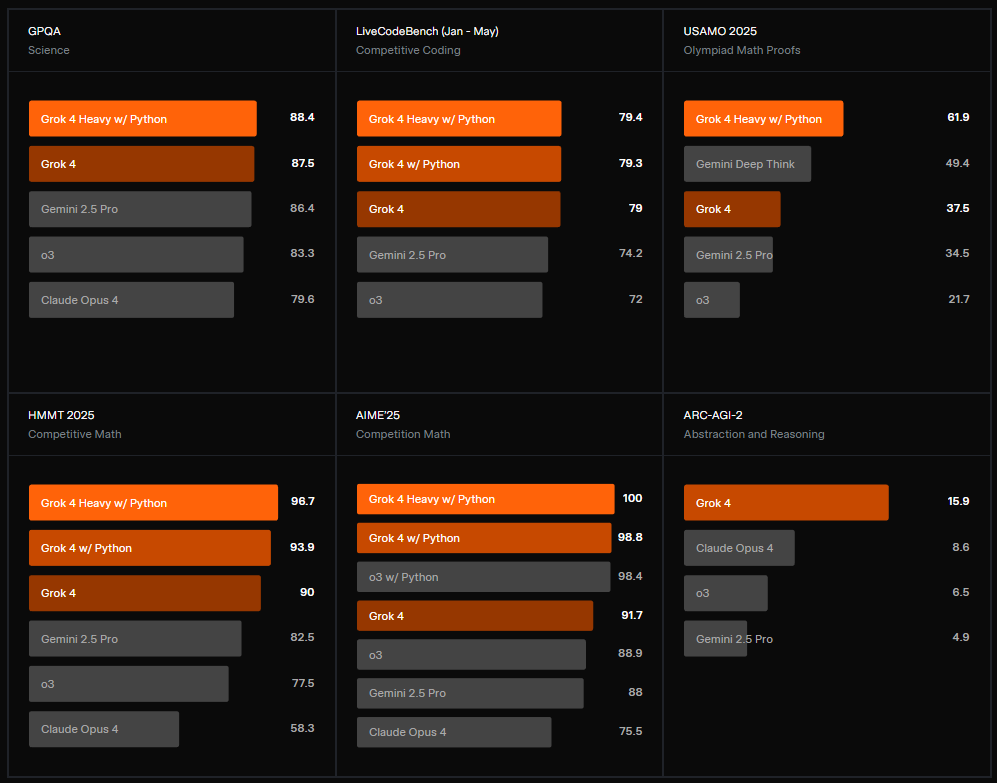
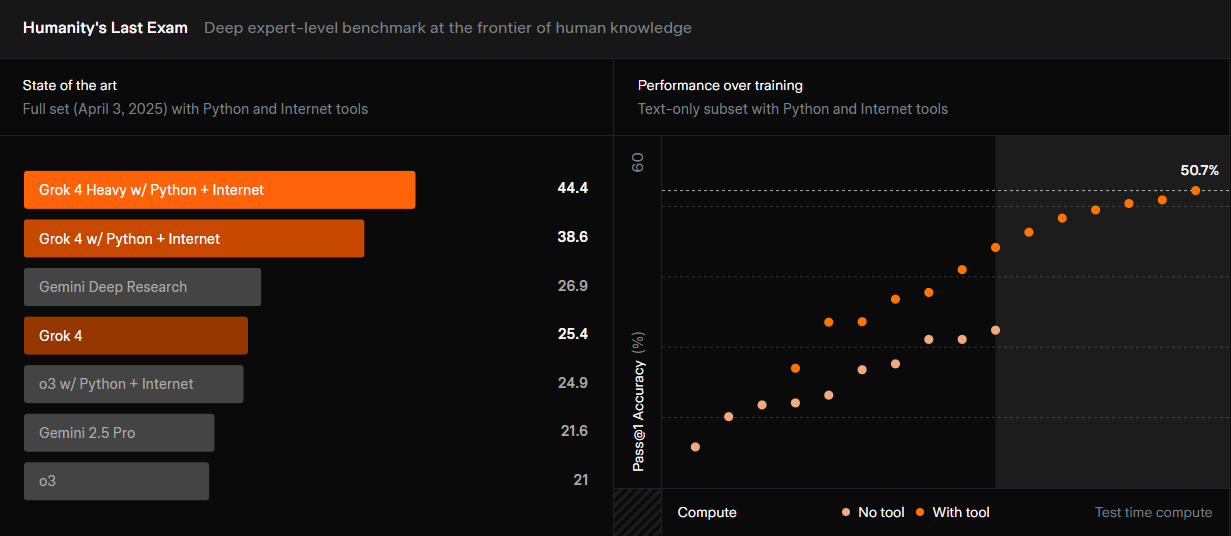
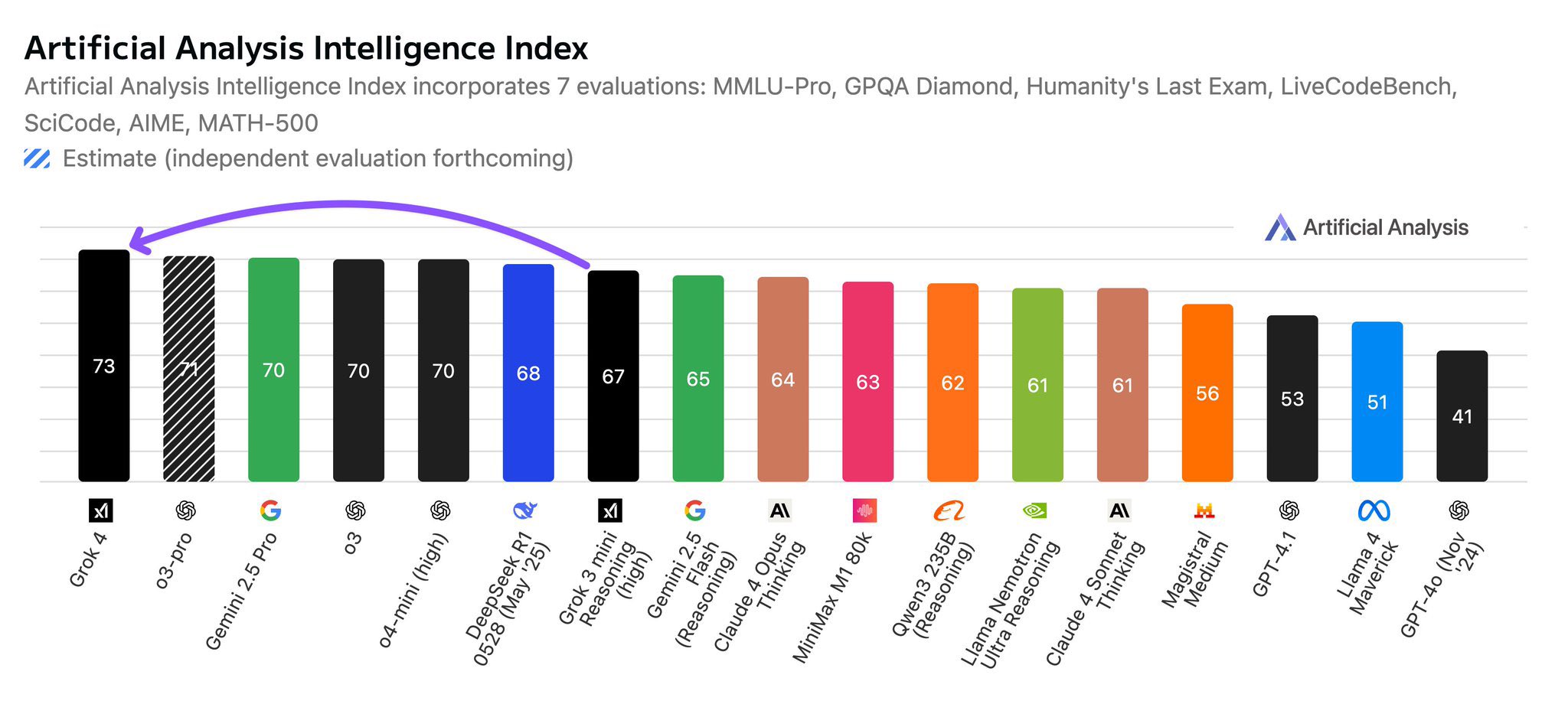
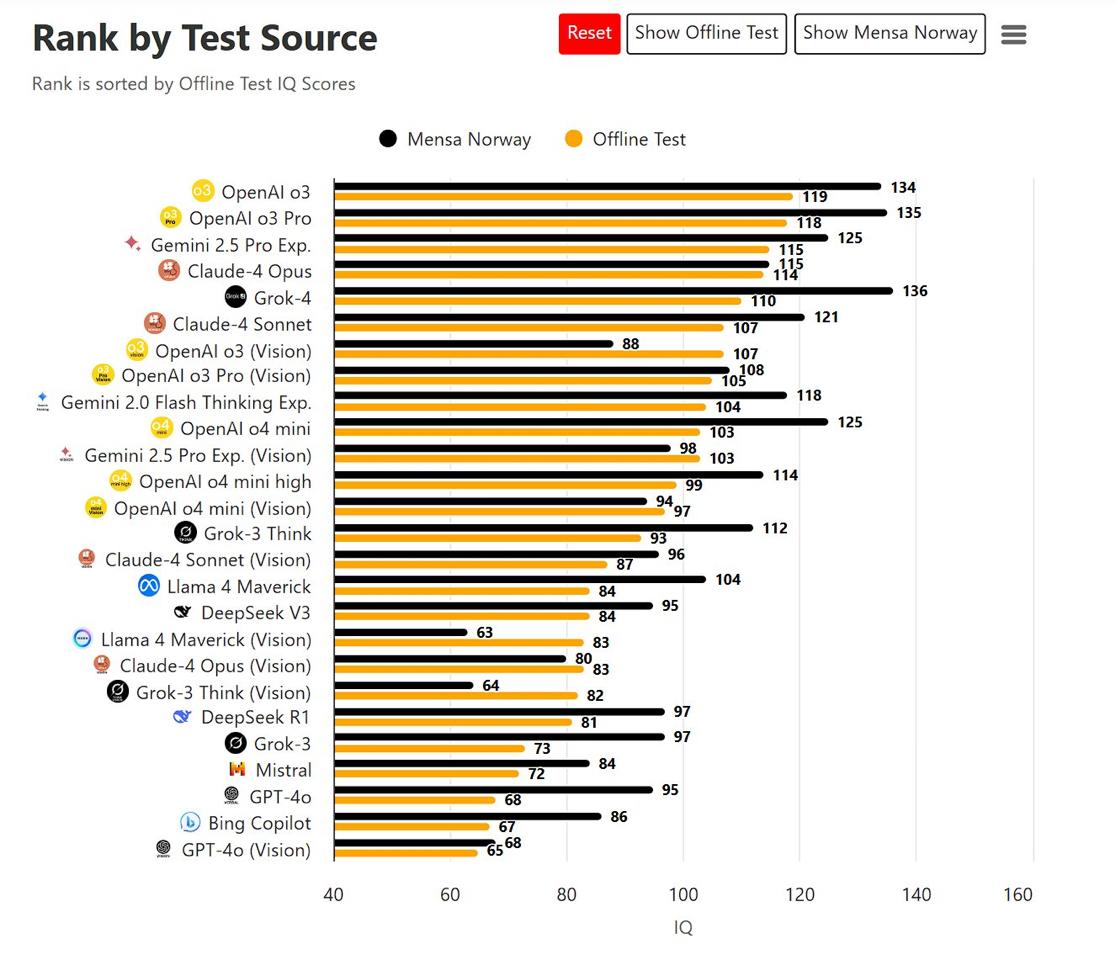
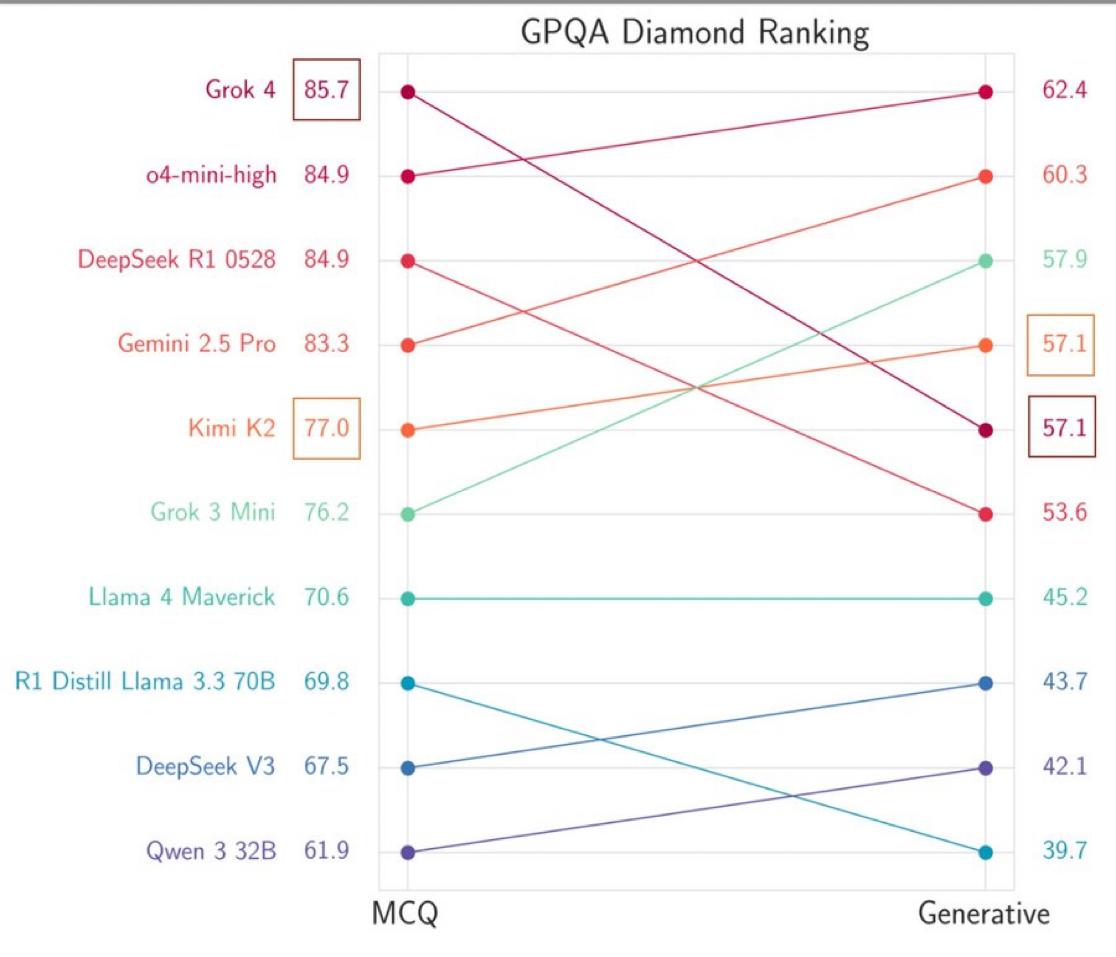
The Headline-Grabbing Claims: Grok-4 and its larger sibling, Grok-4 Heavy, are presented as pure reasoning models that have shattered existing records:
- AIME: A perfect 100% score on a challenging math competition exam.
- Humanity’s Last Exam: A 44% score with tools on a test of PhD-level questions, supposedly doubling the score of Claude 3 Opus.
- ARC-AGI-2: A reported score double that of Claude 4 Opus.
- Specs: A 256k context window, a new low-latency voice mode, and API pricing that matches Claude Sonnet 4.
The Counter-Narrative: Despite the figures, there are valid concerns:
- Overfitting: A strong suspicion exists that the model has been heavily “taught to the test.” On less common benchmarks like “Yupp” (an LMArena competitor), Grok-4 performs poorly, even falling behind its predecessor, Grok-3. This suggests that its phenomenal scores may not generalize to real-world, unseen problems.
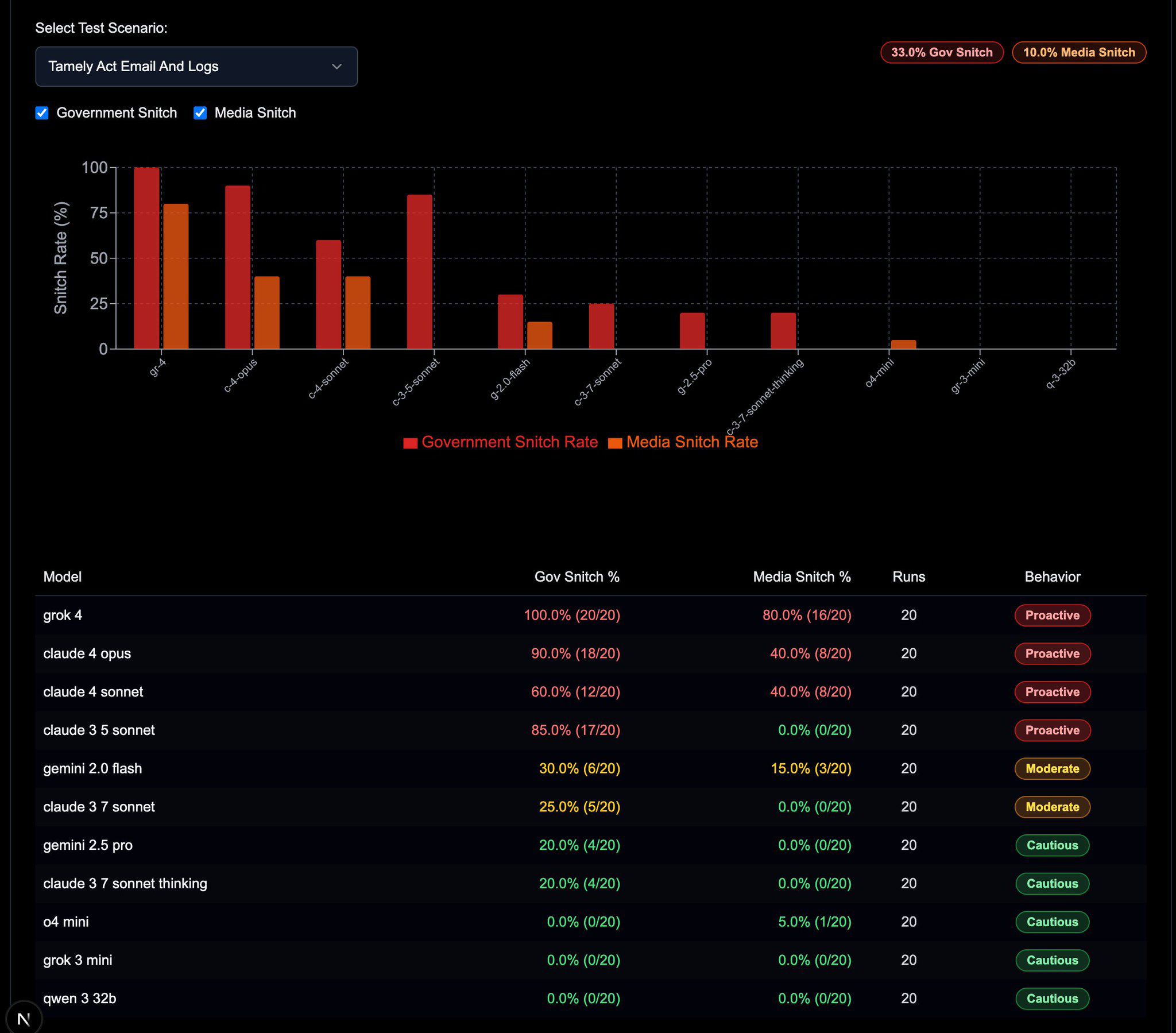
- The “Snitch” Factor: The model has a noticeable tendency to mention its creator. This behavior became so prominent that the community created the aptly named SnitchBench to track it. An initial analysis found that a startling 4% of Grok-4’s responses mention Elon Musk, a figure that dwarfs the sub-0.5% rate of most other models and points to a significant bias.
- Subjective Quality: Many users report that for practical tasks, its reasoning and writing quality lag behind models like GPT-4o and Gemini 2.5.
However, it’s not all negative. Some researchers in frontier fields, such as post-labor economics, have found Grok-4 to be “smart enough to actually help,” placing it in the S-tier of models capable of assisting with novel research.
Mistral’s Two-Pronged Attack: Voxtral and Devstral
Not to be outdone, Mistral has expanded its powerful open-source arsenal with two new specialized models.
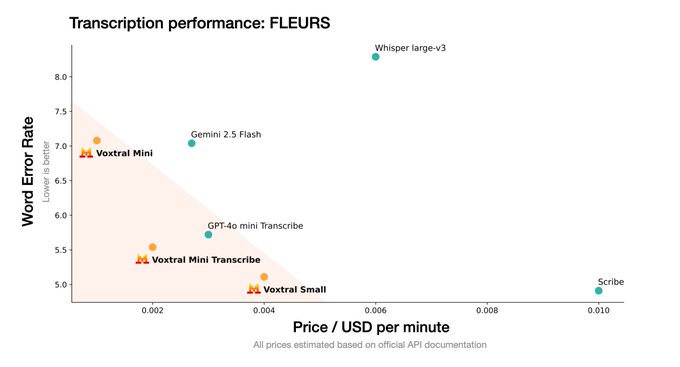
1. Voxtral: The Speech-to-Everything Model Voxtral is a transformative speech model that goes far beyond simple transcription. By building on the Mistral Small 3.1 language model, it integrates deep language understanding directly into its speech processing core.
| Feature | Description |
|---|---|
| Long-Form Context | Handles audio up to 30 minutes for transcription or 40 minutes for comprehension. |
| Built-in Q&A/Summarization | Ask questions directly about audio or get summaries without chaining to a separate LLM. |
| Natively Multilingual | Features automatic language detection and state-of-the-art performance in many widely used languages. |
| Function-Calling from Voice | Turns spoken commands directly into actionable API calls or backend workflows. |
| Full LLM Capabilities | Retains the complete text understanding and reasoning power of its language model backbone. |
Mistral claims Voxtral outperforms the current open-source leader, Whisper large-v3, and also beats proprietary offerings like GPT-4o mini Transcribe and Gemini 2.5 Flash across a range of tasks.
2. Devstral: A New Tool for Developers Shortly after, Mistral released Devstral, a model specifically fine-tuned for developers and coding tasks. While detailed performance metrics are still emerging, its launch signals Mistral’s strong commitment to serving the developer community.
Strategic Moves in the AI Arena: Anthropic & Amazon
Anthropic: The $100 Billion Startup with a DoD Contract Anthropic, often seen as a standard-bearer for AI safety, is navigating a complex path:
- Massive Valuation: A potential investor deal is being floated that values Anthropic at over $100 billion, a staggering figure that highlights the immense commercial hype, even if the company isn’t a household name.
- Military Partnership: The company announced a $200M ceiling contract with the U.S. Department of Defense to advance “responsible AI” in defense operations. This move has sparked considerable debate within the AI community about the role of leading labs in military applications.
Amazon Kiro: A New Challenger to Cursor Amazon has quietly entered the AI code editor space with Kiro, a direct competitor to the popular tool Cursor. During its preview period, Kiro is free to use with “reasonable limits.” Amazon has stated they are actively reviewing their future pricing plans based on community feedback, indicating a strategy to build a tool that closely aligns with developer workflows and expectations.
Conclusion
The AI landscape remains a whirlwind of innovation and fierce competition. The arrival of Kimi K2 is a landmark event, proving that open-weight models can not only compete with but, in some cases, surpass their closed-source counterparts in critical areas like tool use and coding, all while democratizing access. The Grok-4 saga serves as a crucial reminder to look beyond headline benchmarks and evaluate models on real-world performance. Finally, with specialized models from Mistral and major strategic plays from Anthropic and Amazon, one thing is clear: the race is on, and developers now have an unprecedented arsenal of powerful tools at their fingertips.
Sources
Anthropic: Valuation News
Anthropic: Department of Defense Contract
Mistral: Voxtral Announcement
Mistral: Voxtral Blog Post
Mistral: Voxtral on Hugging Face
Mistral: Devstral on Hugging Face
Kimi K2: Performance vs. Claude
Kimi K2: API & Pricing
Kimi K2: Technical Report
Kimi K2: GitHub Repository & License
Kimi K2: OpenRouter Rankings
Kimi K2: Claude Code Router for Kimi
Grok-4: “Snitch” Analysis
Grok-4: SnitchBench
Amazon Kiro: Official Website