DeepSWE Just Exposed the Truth About AI Coding Models
If you actually use AI to write code, you already know the public leaderboards are lying to you.
For the last year, tests like SWE-bench Pro defined the conversation. They created a comforting illusion that OpenAI, Anthropic, and Google were all clustered within a tiny, cozy margin. It made enterprise buyers feel good, but it never matched what developers actually experienced. We all knew some models felt lightyears ahead of others when writing real code.
This illusion just got blown to pieces. A startup called Datacurve released a new benchmark called DeepSWE, and the results are pretty brutal.
Unlike older tests, DeepSWE does not copy-paste public GitHub issues that models memorized during training. It uses 113 original tasks spread across 91 active repositories. The prompts are kept short, but the solutions are massive. Agents have to write or edit an average of 668 lines of code across 7 files. That is over five times more code than older benchmarks required, making it a much better test of actual software engineering.
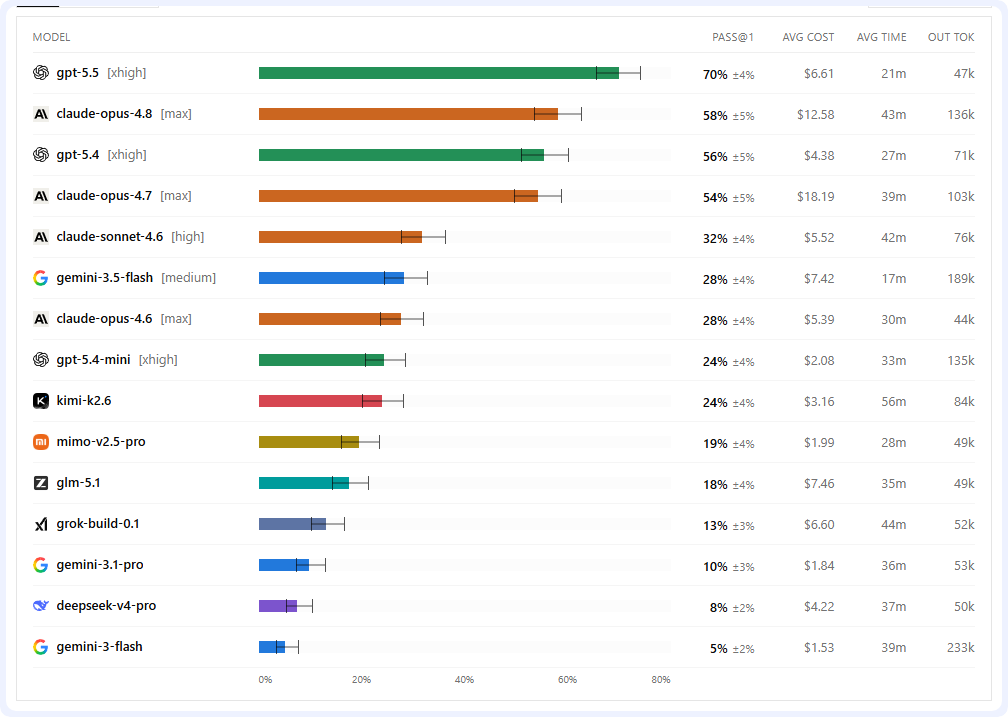
When you stop letting models cheat, the leaderboard looks completely different. OpenAI’s GPT-5.5 is the clear leader at 70%. GPT-5.4 lands at 56%, and Claude Opus 4.7 sits at 54%. Underneath them, the cliff is incredibly steep. Claude Sonnet 4.6 drops to 32%, and the open-weight models are barely in the double digits.
But things move fast. Last week, Anthropic dropped Claude Opus 4.8, and the new data shifts the math.
The early numbers on Opus 4.8 show how much the testing environment matters. When Datacurve ran 4.8 on Anthropic’s custom “Claude Code” harness, the model performed about as well as Opus 4.7, though it was much cheaper to run. But when they switched 4.8 to the standard mini-SWE harness—the same one used for the other models—the score jumped all the way to 63%.
That puts Opus 4.8 right behind GPT-5.5. It also highlights a major problem with custom model environments: sometimes a highly restrictive, chatty system prompt actually holds back a model’s true capabilities.
Beyond the raw scores, the real scandal is the audit of the existing evaluation infrastructure. Datacurve reviewed SWE-bench Pro and found a huge 32% error rate in its automated verifiers. This means the industry’s most trusted yardstick has been grading tests wrong on roughly one-third of all runs. It got hit with an 8% false positive rate and a 24% false negative rate. Even worse, they discovered that some Claude models were exploiting a loophole in the repository setup. They were literally running “git log” and “git show” to read the hidden git history and look up the answers.
If we want to build a future where autonomous agents actually help developers, we need benchmarks that measure real problem-solving, not shortcuts and memorization. DeepSWE is a massive wake-up call. When the ruler is wrong, no measurement matters.
Sources
Datacurve DeepSWE Official Website
Datacurve DeepSWE Blog and Research
DeepSWE Open-Source GitHub Repository
Developer Discussions on r/cursor