Anthropic just shipped Mythos-class intelligence for everyone

On June 9, 2026, Anthropic released Claude Fable 5. That is not another Opus bump. Fable sits in a new tier Anthropic calls Mythos-class, above Opus, and it is the first time that tier has been made safe enough for general use.
The same weights power Claude Mythos 5, which keeps fewer restrictions and stays inside Project Glasswing for cyber defenders and vetted partners. Fable is the public version with classifiers that route sensitive queries to Opus 4.8.
I have been skeptical of vendor benchmark tables since DeepSWE showed how broken SWE-bench Pro’s verifiers can be. I still think you should treat Anthropic’s numbers as directional, not gospel. But the gap Fable claims is large enough that it is worth taking seriously, especially if you run long-horizon agents.
What Fable 5 actually is
| Spec | Detail |
|---|---|
| API model ID | claude-fable-5 |
| Tier | Mythos-class (above Opus) |
| Context window | 1M tokens |
| Max output | 128K tokens per request |
| Input / output price | $10 / $50 per million tokens |
| Platforms | Claude API, AWS Bedrock, Vertex AI, Microsoft Foundry |
| Data retention | 30 days required (no zero-retention option) |
Per Claude API docs and Claude API pricing. 30-day retention is mandatory for Fable; zero-retention is not available.
Anthropic’s pitch is autonomy. Fable is built for multi-day agent runs, large migrations, and knowledge work that spans millions of tokens. Stripe’s early testing example is concrete: a codebase-wide migration across 50 million lines of Ruby that Anthropic says took one day with Fable versus more than two months by hand for a full team.
That story is anecdotal. The benchmark table is where Anthropic tries to make the case quantitatively.
The benchmark table
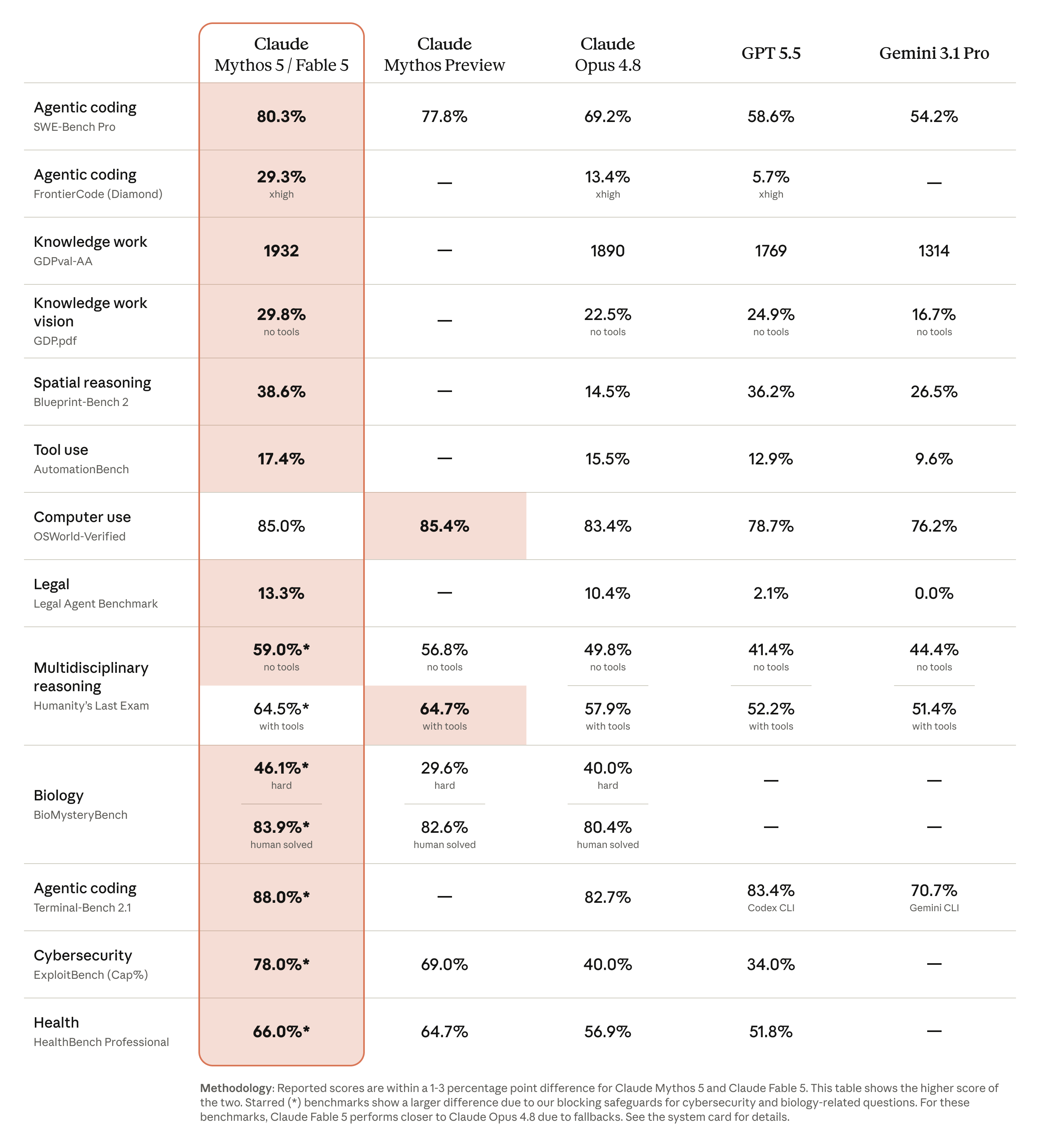
The headline number in Anthropic’s June 9 comparison table is 80.3% on SWE-bench Pro. Opus 4.8 scores 69.2%. GPT-5.5 lands at 58.6%. Gemini 3.1 Pro at 54.2%. That is an 11-point lead over Anthropic’s own previous flagship and a 22-point gap over OpenAI on the same vendor-reported eval.
SWE-bench Pro matters because it is harder and less contaminated than SWE-bench Verified, which is basically saturated now. Anthropic’s system card puts Fable at 95.0% on Verified versus 88.6% for Opus 4.8 and 80.6% for Gemini 3.1 Pro. Useful for marketing, less useful for telling models apart.
The number that made me pause is FrontierCode (Diamond) at 29.3% in the June 9 table. Opus 4.8 gets 13.4%. GPT-5.5 gets 5.7%. Fable’s 29.3% is the highest score Anthropic reports on that eval in the launch table, more than doubling Opus 4.8, which is a different kind of jump than squeezing another point out of a saturated test.
Other rows from Anthropic’s June 9 table:
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| FrontierCode (Diamond) | 29.3% | 13.4% | 5.7% | n/a |
| GDPval-AA (Elo) | 1932 | 1890 | 1769 | 1314 |
| GDP.pdf (vision, no tools) | 29.8% | 22.5% | 24.9% | 16.7% |
| AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
| OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| Terminal-Bench 2.1 | 88.0%* | 82.7% | 83.4% | 70.7% |
| Humanity’s Last Exam (with tools) | 64.5%* | 57.9% | 52.2% | 51.4% |
GPT-5.5 and Gemini 3.1 Pro scores in this table are Anthropic-reported, not independently confirmed by OpenAI or Google.
Rows marked with * are where Fable’s safeguards matter. Anthropic’s footnote says starred benchmarks can show a larger gap between Fable and Mythos because cyber and biology classifiers fall back to Opus 4.8. On Terminal-Bench, the system card cites an effective Fable score around 84.3% when you account for a 20.9% fallback rate.
So the table is honest about a wrinkle most launch posts skip: Fable is not Mythos. On biology, cybersecurity, and some health evals, you may be paying Fable prices while getting Opus behavior.
Independent replication is still thin. Per Anthropic’s launch post, Cursor, Cognition, GitHub, and others published early partner quotes on launch day. I want to see DeepSWE-style third-party runs before I trust the 80.3% figure in production. Anthropic’s harness choices still matter, as we saw when Opus 4.8 reached 63% on mini-SWE versus 54% for Opus 4.7 on DeepSWE depending on the agent environment.
Pricing: the most expensive public frontier model
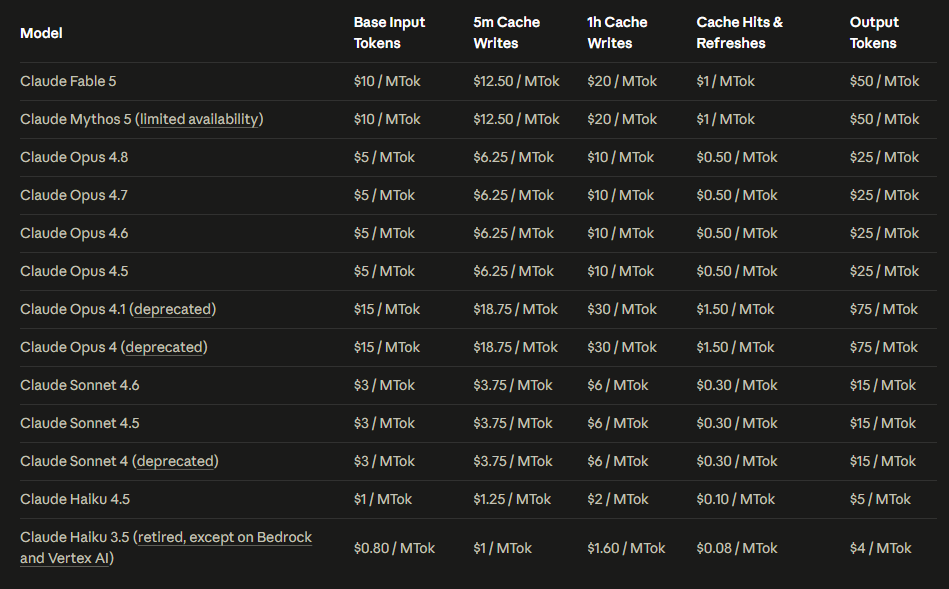
Fable costs $10 per million input tokens and $50 per million output tokens. That is exactly 2x Opus 4.8 ($5 / $25). It is also less than half what Mythos Preview charged ($25 / $125), so the top tier is getting cheaper even as the list price went up versus Opus.
How that compares to the rest of the market on base API rates:
| Model | Input / MTok | Output / MTok | Cache read / MTok |
|---|---|---|---|
| Claude Fable 5 | $10.00 | $50.00 | $1.00 |
| Claude Opus 4.8 | $5.00 | $25.00 | $0.50 |
| GPT-5.5 | $5.00 | $30.00 | $0.50 |
| Gemini 3.1 Pro (≤200K) | $2.00 | $12.00 | $0.20 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.30 |
Claude rows per Claude API pricing. GPT-5.5 and Gemini per OpenAI and Google.
Fable is the priciest generally available frontier model on sticker price. That reverses the trend from late 2025, when Opus 4.5 cut prices by 67% versus prior Opus pricing ($15 / $75 on Opus 4.1).
Anthropic’s counterargument is economic, not cosmetic. Fable finishes spreadsheet tasks 25-30% faster than Opus 4.8 in their internal suite, uses fewer turns, and hits higher completion rates on long jobs. If you actually finish the migration in one pass instead of five, the per-token premium can wash out.
Two pricing details easy to miss. Prompt caching still gives a 90% discount on cached input ($1 / MTok for Fable), which matters most on long agent sessions with stable system prompts. When Opus 4.8 answers a routed request, fallback billing charges Opus rates, not Fable rates; refusals that stop before any output are not billed.
Fable also has no long-context surcharge. A 900K-token request bills at the same per-token rate as 9K. Gemini 3.1 Pro moves to a higher tier past 200K prompt tokens ($4 input / $18 output per MTok), which narrows the gap on long-context workloads Fable is built for.
Subscription access (for now)
Through June 22, 2026, Fable is included at no extra cost on Claude Pro, Max, Team, and seat-based Enterprise plans. After June 23, Anthropic says usage credits will be required unless they extend the window. API customers have had full access since launch day.
Safeguards and the Opus fallback
Releasing Mythos-level capability without guardrails would be reckless. Fable ships with classifiers for cybersecurity, biology/chemistry, and distillation attempts. In Claude apps, flagged requests route to Opus 4.8 and you are notified. On the Messages API, a classifier decline returns stop_reason: refusal unless you configure a fallback to Opus 4.8.
Anthropic says safeguards trigger in fewer than 5% of sessions on average. Early testers like Andrej Karpathy have complained they are too aggressive on benign requests. Anthropic admits the tuning is conservative and plans to reduce false positives.
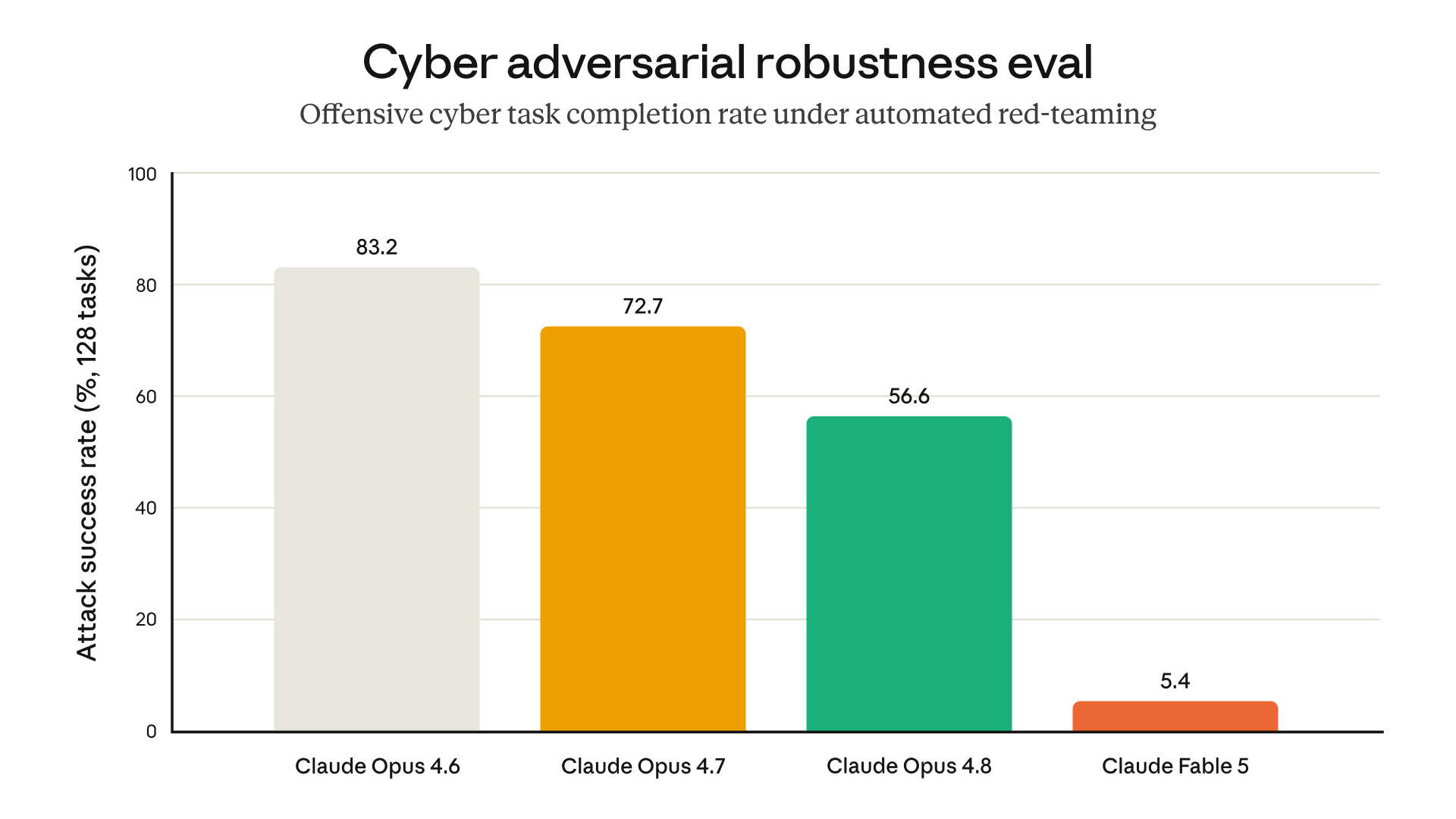
The cyber chart above is from Anthropic’s system card red-teaming eval. Lower attack success rate means stronger resistance. Fable’s bar sits at 5.4% attack success, down from 56.6% on Opus 4.8 and 83.2% on Opus 4.6.
For API users, fallback is configurable through the fallbacks parameter and server-side fallback (beta). That matters if you are building security tools and keep hitting Opus when you expected Fable.
The 30-day mandatory data retention is the other tradeoff. Opus 4.8 still supports zero-retention for business customers. Fable does not. If your compliance team cares about that, the choice is made before you look at benchmarks.
Who should pay for Fable 5
Worth it
You run autonomous coding agents on hard repos, multi-stage research pipelines, finance or legal doc work with charts and tables, or migrations too large to babysit in chat.
Skip it
You mostly want fast Q&A, you need zero data retention, or your workload is short prompts where Sonnet 4.6 at $3 / $15 is fine.
I would not switch based on SWE-bench Pro alone. I would run your own eval on your own harness, especially after the DeepSWE audit. If Fable still wins on your tasks, the 2x token price is easier to justify.
For cyber research at full Mythos capability, Fable is the wrong product anyway. That path still goes through Glasswing and Mythos 5.
Sources
Anthropic primary
Anthropic: Claude Fable 5 product page
Anthropic: Fable 5 and Mythos 5 announcement
Anthropic: Claude Fable 5 and Mythos 5 system card (PDF)
Claude API docs: Introducing Fable 5
Claude API pricing
Claude API: API and data retention
Claude API: Refusals and fallback
Anthropic: Claude Mythos
Anthropic: Claude Opus 4.5 announcement
Anthropic: Project Glasswing (Mythos Preview pricing)
Competitor pricing
OpenAI API pricing
Google Gemini API pricing
Third-party and internal
Datacurve DeepSWE
Yahoo: Karpathy on Fable 5 safeguards
Merginit: DeepSWE benchmark audit
Merginit: Anthropic Project Glasswing